
迁移学习在深度学习领域是一种很流行的方法:面对新问题,不是从零开始学习,而是从之前解决各种类似问题时学到的模式开始学习。这样,就可以在解决新问题时利用以前的学习成果(预训练模型)。
预训练模型 (Pre-Trained Model)
预训练模型 (Pre-Trained Model) 是指已经在大型基准数据集上训练好的模型,用于解决相似的问题。由于训练这种模型的计算成本较高,因此,导入已发布的开源成果并使用相应的开源模型是比较常见的做法。
微调 (Fine-tune)
获取预训练模型后,根据实际问题修改模型尾端的输出部分,使之与实际问题的要求匹配,然后根据情况从以下的三种策略中选择一种,将实际问题的数据输入预训练模型进行训练(这一步过程就称为微调):
- 训练整个模型:保留预训练模型的结构,以预训练模型学习到的参数作为初始参数,将实际问题的数据集输入整个预训练模型对所有参数进行训练:
- 这种微调方式需要较多的计算资源,且实际问题的数据集规模要与预训练模型的参数规模匹配;
- 训练部分层:如果认为模型的靠前层提取的是通用特征(独立于具体问题的特征:例如,NLP 中的一些通用语义特征、CV 中的一些通用的形状特征),而靠后层提取的是特殊特征(与具体的分类或回归结果强相关的特征:例如,猫狗分类中的狗尾巴、情感分析中能体现具体情感的单词等);则可以在微调时,冻结预训练模型的靠前层(这部分通用特征已经在大规模的基准数据上训练好了),仅仅对靠后层(这部分特殊特征需要在实际问题的数据上拟合)使用实际问题的数据进行训练:
- 通常,如果实际问题的数据集较小,而预训练模型的参数量较大,则需要冻结更多的层,以避免在少量数据上过拟合;
- 如果实际问题的数据集较大,而预训练模型的参数量较小(数据量足够多,不容易过拟合),那么可以给新任务训练更多的层来完善模型,从而提高模型的准确率;
- 仅训练输出层:考虑把预训练模型作为固定的特征提取器,冻结除了输出层以外的所有层,仅对输出层使用实际问题的数据进行训练:
- 如果缺少计算资源,并且实际问题的数据集很小,或者预训练模型的效果已经能够满足实际要求,则可以使用这种微调方式;
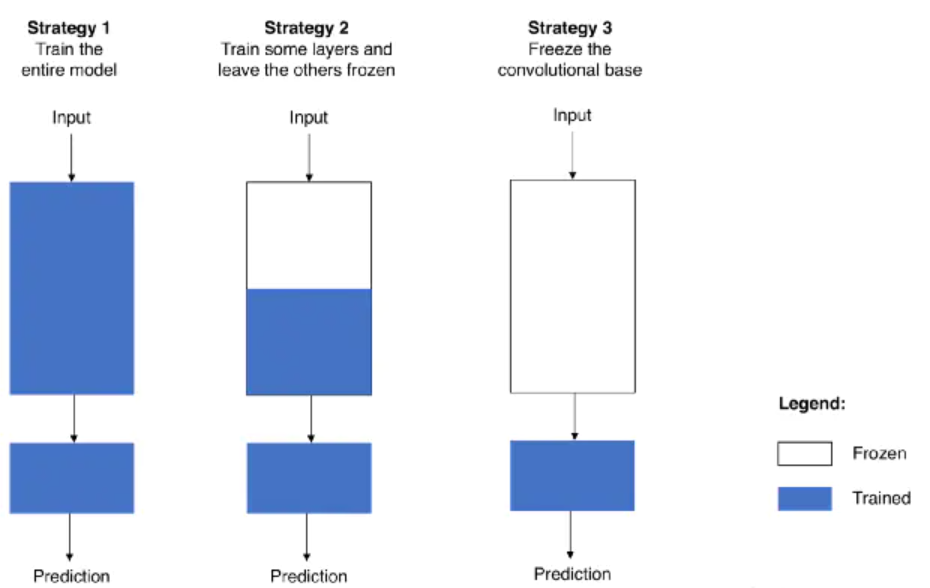
微调策略的选择
根据下图的指示对微调策略进行选择:纵坐标表示实际问题的数据集的规模,横坐标则表示实际问题的数据集与预训练时使用的基准数据集的相似程度:(在 CV 领域,根据经验,如果每个类的图像少于 1000 张,则认为是小数据集;数据集的相似性则依靠常识来判定:例如,如果实际任务是识别猫和狗,那么 ImageNet 将是一个类似的基准数据集,因为它有猫和狗的图像;如果实际任务是识别癌细胞,则不包含相关图像的 ImageNet 就不够相似了)
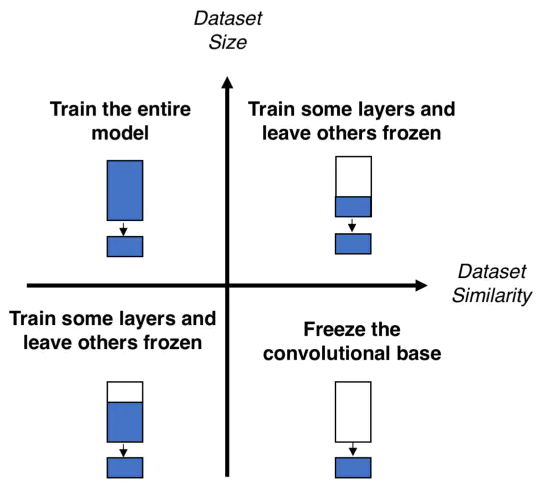
象限一:大数据集,但与预训练基准数据集不相似。这种情况将会让你使用策略 1 训练整个模型:
- 因为有一个大数据集,完全可以支撑我们从零开始训练一个模型;
- 尽管数据集并不相似,但在实践中,利用预训练模型的体系结构和权重,对初始化模型仍然是很有帮助的;
象限二:大数据集,且与预训练基准数据集相似。这是最理想的情况,在这种情形下三种策略都有效,可能最有效的是策略 2 训练部分层:
- 由于有一个较大数据集,过拟合将不会是一个严重问题,所以能够尽可能地开放较多的参数在新数据上进行学习;
- 同时,由于数据集是相似的,其实可以利用以前的知识来节省大量的训练过程,因此,尽可能地冻结较多的参数,仅对必要的部分参数进行微调也是可行的;
综合考虑,为了节省计算资源,使用后者会更加理想;
象限三:小数据集,且与预训练基准数据集不相似。这是最不理想的情况,唯一适合的就是策略 2 训练部分层。这种情况下很难在训练和冻结的层数之间取得平衡:
- 如果冻结的层数过少,那么由于实际问题的数据量不足,模型很可能过拟合;
- 如果冻结的层数过多,那么模型很难从新数据集上学到新的知识,模型还是只能适用于预训练基准数据集(而这个数据集与实际问题的数据集并不相似),造成欠拟合;
在这种情况下,需要考虑使用数据增强技术扩大实际问题数据集,或是使用其他改进方法;
象限四:小数据集,且与预训练基准数据集相似。这种情况将会让你使用策略 3 仅训练输出层:
数据集较小,不够支撑对模型过多参数的训练(若开放过多参数进行训练容易陷入对这些少量数据的过拟合);
数据集之间非常相似,所以模型在预训练基准数据集上学到的知识可以直接迁移到实际问题的数据集上;